
연관관계를 가진 두 엔티티 중 한쪽의 데이터만 필요해서 조회하려고 할 때, 나머지 반대쪽 엔티티도 조회할 필요는 없을 것이다.
그것은 리소스 낭비이다.
JPA에서 이와 관련된 문제가 즉시로딩과 지연로딩이다.
코드로 먼저 지연로딩(LAZY) 이해하기
member 엔티티와 team 엔티티가 N:1 관계로 양방향 설정이 되어있다.
FetchType 속성은 @ManyToOne 에서 사용한다.
이번 코드에서는 FetchType.LAZY 를 설정하였다.
- member 엔티티
@Entity
@Getter
@Setter
public class Member extends BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "name")
private String username;
private Integer age;
@Enumerated(EnumType.STRING)
private RoleType roleType;
@Lob
private String description;
// 패치 타입 LAZY 설정
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "team_id", insertable = false, updatable = false)
private Team team;
@OneToOne
@JoinColumn(name = "locker_id")
private Locker locker;
@OneToMany(mappedBy = "member")
private List<MemberProduct> memberProducts = new ArrayList<>();
public void changeTeam(Team team) {
this.team = team;
this.team.getMembers().add(this);
}
}이제 main 함수에서 member와 team을 저장하고 member 엔티티 조회하고 getTeam() 을 통해 team 엔티티를 가져와보자.
- main
Team team = new Team();
team.setName("teamA");
em.persist(team);
Member member = new Member();
member.setUsername("memberA");
em.persist(member);
member.changeTeam(team);
em.flush();
em.clear();
Member findMember = em.find(Member.class, member.getId());
System.out.println(findMember.getTeam().getClass());- 쿼리 결과
Hibernate:
select
member0_.id as id1_4_0_,
member0_.createdBy as createdB2_4_0_,
member0_.createdDate as createdD3_4_0_,
member0_.lastModifiedBy as lastModi4_4_0_,
member0_.lastModifiedDate as lastModi5_4_0_,
member0_.age as age6_4_0_,
member0_.description as descript7_4_0_,
member0_.locker_id as locker_10_4_0_,
member0_.roleType as roleType8_4_0_,
member0_.team_id as team_id11_4_0_,
member0_.name as name9_4_0_,
locker1_.id as id1_3_1_,
locker1_.name as name2_3_1_
from
Member member0_
left outer join
Locker locker1_
on member0_.locker_id=locker1_.id
where
member0_.id=?
class hello.jpa.Team$HibernateProxy$e97rdqZR // 프록시 객체쿼리 결과에서 확인할 수 있는 것은 team 엔티티에 대한 프록시 객체가 조회된다는 점이다.
이는 FetchType.LAZY 를 설정했기 때문이다.
여기서 team 엔티티에서 실제로 데이터가 필요해서 '팀 이름'을 조회해보자.
Team team = new Team();
team.setName("teamA");
em.persist(team);
Member member = new Member();
member.setUsername("memberA");
em.persist(member);
member.changeTeam(team);
em.flush();
em.clear();
Member findMember = em.find(Member.class, member.getId());
System.out.println(findMember.getTeam().getClass());
System.out.println("TEAM NAME : " + findMember.getTeam().getName());- 쿼리 결과
Hibernate:
select
member0_.id as id1_4_0_,
member0_.createdBy as createdB2_4_0_,
member0_.createdDate as createdD3_4_0_,
member0_.lastModifiedBy as lastModi4_4_0_,
member0_.lastModifiedDate as lastModi5_4_0_,
member0_.age as age6_4_0_,
member0_.description as descript7_4_0_,
member0_.locker_id as locker_10_4_0_,
member0_.roleType as roleType8_4_0_,
member0_.team_id as team_id11_4_0_,
member0_.name as name9_4_0_,
locker1_.id as id1_3_1_,
locker1_.name as name2_3_1_
from
Member member0_
left outer join
Locker locker1_
on member0_.locker_id=locker1_.id
where
member0_.id=?
class hello.jpa.Team$HibernateProxy$z4JtUeLD // 프록시 객체
Hibernate:
select
team0_.id as id1_8_0_,
team0_.createdBy as createdB2_8_0_,
team0_.createdDate as createdD3_8_0_,
team0_.lastModifiedBy as lastModi4_8_0_,
team0_.lastModifiedDate as lastModi5_8_0_,
team0_.name as name6_8_0_
from
Team team0_
where
team0_.id=?
TEAM NAME : teamA이제서야 실제로 team 을 조회하는 쿼리가 발생하는 것을 알 수 있다.
지연로딩(LAZY) 동작
앞선 예제 코드에서 확인했듯이, 로딩 시점에서 Lazy 설정이 되어있는 엔티티는 먼저 프록시 객체를 가져온다.
후에 실제로 객체를 사용하는 시점에 쿼리가 나간다.
만약 많은 비즈니스 로직에서 두 엔티티가 함께 쓰인다면?
이럴 경우 LAZY 를 사용하면 SELECT 쿼리가 각각 2번 나가므로 리소스 낭비이다.
따라서 EAGER 를 사용해 즉시로딩을 통해 한번에 조회하면 된다.
즉시로딩(EAGER)
대부분의 JPA 구현체는 JOIN 을 사용해 쿼리를 날려 한번에 데이터를 가져오려고 한다.
EAGER 를 사용하면 프록시 객체도 사용하지 않는다.
@Entity
@Getter
@Setter
public class Member extends BaseEntity {
...
@ManyToOne(fetch = FetchType.EAGER)
@JoinColumn(name = "team_id", insertable = false, updatable = false)
private Team team;
...
}Team team = new Team();
team.setName("teamA");
em.persist(team);
Member member = new Member();
member.setUsername("memberA");
em.persist(member);
member.changeTeam(team);
em.flush();
em.clear();
Member findMember = em.find(Member.class, member.getId());
System.out.println(findMember.getTeam().getClass());
System.out.println("TEAM NAME : " + findMember.getTeam().getName());
tx.commit();실행 결과
Hibernate:
select
member0_.id as id1_4_0_,
member0_.createdBy as createdB2_4_0_,
member0_.createdDate as createdD3_4_0_,
member0_.lastModifiedBy as lastModi4_4_0_,
member0_.lastModifiedDate as lastModi5_4_0_,
member0_.age as age6_4_0_,
member0_.description as descript7_4_0_,
member0_.locker_id as locker_10_4_0_,
member0_.roleType as roleType8_4_0_,
member0_.team_id as team_id11_4_0_,
member0_.name as name9_4_0_,
locker1_.id as id1_3_1_,
locker1_.name as name2_3_1_,
team2_.id as id1_8_2_,
team2_.createdBy as createdB2_8_2_,
team2_.createdDate as createdD3_8_2_,
team2_.lastModifiedBy as lastModi4_8_2_,
team2_.lastModifiedDate as lastModi5_8_2_,
team2_.name as name6_8_2_
from
Member member0_
left outer join
Locker locker1_
on member0_.locker_id=locker1_.id
left outer join
Team team2_
on member0_.team_id=team2_.id
where
member0_.id=?
class hello.jpa.Team
TEAM NAME : teamA
실무에서는 거의 지연로딩을 사용한다. 즉시로딩은 예상치 못한 쿼리를 발생하는 경우도 있고 너무 많은 쿼리를 발생할 수도 있다. 예를 들어 @ManyToOne 이 5개일 때, 모두 즉시로딩이라면 JOIN 만 5번이 발생한다.
N+1 문제
- 연관 관계가 설정된 엔티티를 조회할 경우에 조회된 데이터 갯수(n) 만큼 연관관계의 조회 쿼리가 추가로 발생하여 데이터를 읽어오는 현상.
원인
- jpaRepository에 정의한 인터페이스 메서드를 실행하면 JPA는 메서드 이름을 분석해서 JPQL을 생성하여 실행하게 된다. JPQL은 SQL을 추상화한 객체지향 쿼리 언어로서 특정 SQL에 종속되지 않고 엔티티 객체와 필드 이름을 가지고 쿼리를 한다. 그렇기 때문에 JPQL은 findAll()이란 메소드를 수행하였을 때 해당 엔티티를 조회하는 select * from Owner 쿼리만 실행하게 되는것이다. JPQL 입장에서는 연관관계 데이터를 무시하고 해당 엔티티 기준으로 쿼리를 조회하기 때문이다. 그렇기 때문에 연관된 엔티티 데이터가 필요한 경우, FetchType으로 지정한 시점에 조회를 별도로 호출하게 된다.
지연로딩으로 해결되는가?
LAZY 든 EAGER 든 N+1 문제를 해결하지는 않는다. 쿼리를 날릴 시점이 다를 뿐이지 N+1 문제는 그대로이다.
- EAGER 의 경우
- findAll()을 한 순간 select t from Team t 이라는 JPQL 구문이 생성되고 해당 구문을 분석한 select * from team 이라는 SQL이 생성되어 실행된다. ( SQL 로그 중 Hibernate: select team0_.id as id1_0_, team0_.name as name2_0_ from team team0_ 부분 )
- DB의 결과를 받아 team 엔티티의 인스턴스들을 생성한다.
- team과 연관되어 있는 member 도 로딩을 해야 한다.
- 영속성 컨텍스트에서 연관된 member가 있는지 확인한다.
- 영속성 컨텍스트에 없다면 2에서 만들어진 team 인스턴스들 개수에 맞게 select * from member where team_id = ? 이라는 SQL 구문이 생성된다. ( N+1 발생 )
- LAZY 의 경우
- findAll()을 한 순간 select t from Team t 이라는 JPQL 구문이 생성되고 해당 구문을 분석한 select * from team 이라는 SQL이 생성되어 실행된다. ( SQL 로그 중 Hibernate: select team0_.id as id1_0_, team0_.name as name2_0_ from team team0_ 부분 )
- DB의 결과를 받아 team 엔티티의 인스턴스들을 생성한다.
- 코드 중에서 team 의 member 객체를 사용하려고 하는 시점에 영속성 컨텍스트에서 연관된 member가 있는지 확인한다
- 영속성 컨텍스트에 없다면 2에서 만들어진 team 인스턴스들 개수에 맞게 select * from member where team_id = ? 이라는 SQL 구문이 생성된다. ( N+1 발생 )
해결방법
Fetch Join
우리가 원하는 쿼리는 사실 select * from team left join member on member.team_id = team.id 일 것이다. 이를 직접 지정해주면 된다.
결과는 Inner Join 으로 호출된다.
하지만 단점이 있다. 한번에 다 불러오기 때문에 FetchType.LAZY 를 활용할 수 없고, 페이징도 활용할 수 없다.
@Query("select t from Team t join fetch t.member")
List<Owner> findAllJoinFetch();EntityGraph
@EntityGraph 의 attributePaths에 쿼리 수행시 바로 가져올 필드명을 지정하면 Lazy가 아닌 Eager 조회로 가져오게 된다. Fetch join과 동일하게 JPQL을 사용하여 query 문을 작성하고 필요한 연관관계를 EntityGraph에 설정하면 된다. 그리고 Fetch join과는 다르게 join 문이 outer join으로 실행되는 것을 확인할 수 있다.
@EntityGraph(attributePaths = "member")
@Query("select t from Team t")
List<Team> findAllEntityGraph();👉 Fetch Join 과 EntityGraph 주의할 점
Fetch Join과 EntityGraph는 JPQL을 사용하여 JOIN문을 호출한다는 공통점이 있다. 또한, 공통적으로 카테시안 곱(Cartesian Product)이 발생하여 Owner의 수만큼 Cat이 중복 데이터가 존재할 수 있다. 그러므로 중복된 데이터가 컬렉션에 존재하지 않도록 주의해야 한다.
그렇다면 어떻게 중복된 데이터를 제거할 수 있을까?
- JPQL을 사용하기 때문에 distinct를 사용하여 중복된 데이터를 조회하지 않을 수 있다.
-
컬렉션을 Set을 사용하게 되면 중복을 허용하지 않는 자료구조이기 때문에 중복된 데이터를 제거할 수 있다.
FetchMode.SUBSELECT
두번의 쿼리로 해결하는 방법이다. 해당 엔티티를 조회하는 쿼리는 그대로 발생하고 연관관계의 데이터를 조회할 때 서브 쿼리로 함께 조회하는 방법이다.
@Fetch(FetchMode.SUBSELECT)
@OneToMany(mappedBy = "team", fetch = FetchType.EAGER)
private Set<Member> members = new LinkedHashSet<>();우리 코드와는 다른 그림이지만 결과를 살펴보자. team을 owner, member을 cat 으로 바꿔서 보면 된다.

BatchSize
하이버네이트가 제공하는 org.hibernate.annotations.BatchSize 어노테이션을 이용하면 연관된 엔티티를 조회할 때 지정된 size 만큼 SQL의 IN절 내부인자 개수를 지정하여 쿼리를 날린다.
@BatchSize(size=5)
@OneToMany(mappedBy = "team", fetch = FetchType.EAGER)
private Set<Member> members = new LinkedHashSet<>();@BatchSize가 있으므로 Member의 row 갯수만큼 추가 SQL을 날리지 않고, 조회한 Team 의 id들을 모아서 SQL IN 절을 날린다.
역시 우리 코드와 다른 그림이지만 결과를 살펴보자..
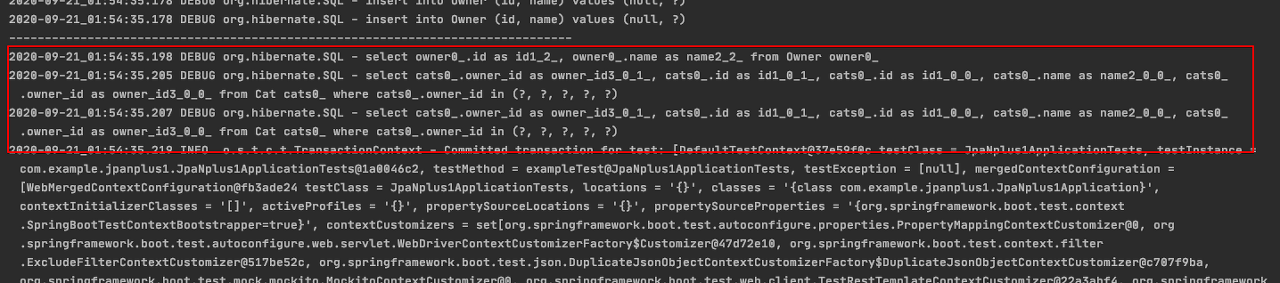
추가적으로 hibernate.default_batch_fetch_size 속성을 사용하면 애플리케이션 전체에 기본으로 @BatchSize를 적용할 수 있다.
<property name="hibernate.default_batch_fetch_size" value="5" />QueryBuilder
// QueryDSL로 구현한 예제
return from(owner).leftJoin(owner.cats, cat)
.fetchJoin()요약
-
Fetch Join이나 EntityGraph를 사용한다면 Join문을 이용하여 하나의 쿼리로 해결할 수 있지만 중복 데이터 관리가 필요하고 FetchType을 어떻게 사용할지에 따라 달라질 수 있다.
-
SUBSELECT는 두번의 쿼리로 실행되지만 FethType을 EAGER로 설정해두어야 한다는 단점이 있다.
-
BatchSize는 연관관계의 데이터 사이즈를 정확하게 알 수 있다면 최적화할 수 있는 size를 구할 수 있겠지만 사실상 연관 관계 데이터의 최적화 데이터 사이즈를 알기는 쉽지 않다.
-
JPA 만으로는 실제 비즈니스 로직을 모두 구현하기 부족할 수 있다. JPA는 만능이 아니다. 간단한 구현은 JPA를 사용하여 프로젝트의 퍼포먼스를 향상 시킬수 있겠지만 다양한 비즈니스 로직을 복잡한 쿼리를 통해서 구현하다보면 다양한 난관에 부딪힐 수 있다. 그리고 불필요한 쿼리도 항상 조심해야 한다. 그러므로 QueryBuilder를 함께 사용하는 것을 추천한다. 그러면 생각보다 다양한 이슈를 큰 고민없이 바로 해결할 수 있다.
참고한 곳
https://programmer93.tistory.com/83
https://incheol-jung.gitbook.io/docs/q-and-a/spring/n+1
https://ict-nroo.tistory.com/132
'Spring > Spring Data JPA' 카테고리의 다른 글
| JPA, JDBC, SPRING, TRANSACTION (0) | 2023.02.19 |
|---|---|
| [스프링과 JPA를 이용한 웹개발] 1강 (0) | 2022.11.08 |